编写层次聚类算法

我们可以使用优先队列来实现这个聚类算法。
什么是优先队列呢?
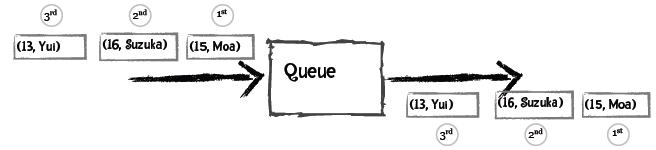
普通的队列有“先进先出”的规则,比如向队列先后添加Moa、Suzuka、Yui,取出时得到的也是Moa、Suzuka、Yui:
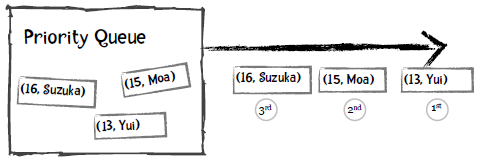
而对于优先队列,每个元素都可以附加一个优先级,从队列中取出时会得到优先级最高的元素。比如说,我们定义年龄越小优先级越高,以下是插入过程:

取出的第一个元素是Yui,因为她的年龄最小:
我们看看Python中如何使用优先队列:
>>> from Queue import PriorityQueue # 加载优先队列类
>>> singersQueue = PriorityQueue() # 创建对象
>>> singersQueue.put((16, 'Suzuka Nakamoto')) # 插入元素
>>> singersQueue.put((15, 'Moa Kikuchi'))
>>> singersQueue.put((14, 'Yui Mizuno'))
>>> singersQueue.put((17, 'Ayaka Sasaki'))
>>> singersQueue.get() # 获取第一个元素,即最年轻的歌手Yui。
(14, 'Yui Mizuno')
>>> singersQueue.get()
(15, 'Moa Kikuchi')
>>> singersQueue.get()
(16, 'Suzuka Nakamoto')
>>> singersQueue.get()
(17, 'Ayaka Sasaki')
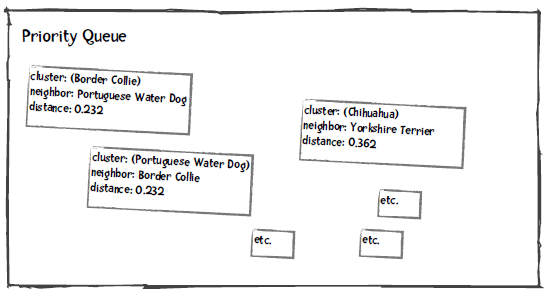
在进行聚类时,我们将分类、离它最近的分类、以及距离插入到优先队列中,距离作为优先级。比如上面的犬种示例,Border Collie最近的分类是Portuguese WD,距离是0.232:
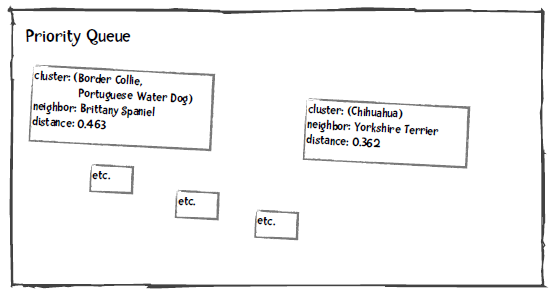
我们将优先队列中距离最小的两个分类取出来,合并成一个分类,并重新插入到优先队列中。比如下图是将Border Collie和Portuguese WD合并后的结果:
重复这个过程,直到队列中只有一个元素为止。当然,我们插入的数据会复杂一些,请看下面的讲解。
从文件中读取数据
数据文件是CSV格式的(以逗号分隔),第一行是列名,第一列是犬种,第二列之后是特征值:
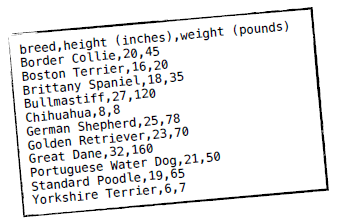
我们用Python的列表结构来存储这些数据,data[0]用来存放所有记录的分类,如data[0][0]是Border Collie,data[0][1]是Boston Terrier。data[1]则是所有记录的高度,data[2]是重量。
特征列的数据都会转换成浮点类型,如data[1][0]是20.0,data[2][0]是45.0等。在读取数据时就需要对其进行标准化。此外,我们接下来会使用“下标”这个术语,如第一条记录Border Collie的下标是0,第二条记录Boston Terrier下标是1等。
初始化优先队列
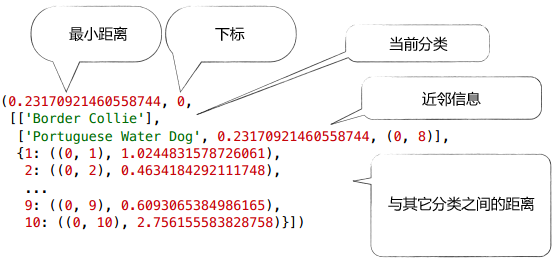
以Border Collie为例,我们需要计算它和其它犬种的距离,保存在Python字典里:
{1: ((0, 1), 1.0244), # Border Collie(下标为0)和Boston Terrier(下标为1)之间的距离为1.0244
2: ((0, 2), 0.463), # Border Collie和Brittany Spaniel(下标为2)之间的距离为0.463
...
10: ((0, 10), 2.756)} # Border Collie和Yorkshire Terrier的距离为2.756
此外,我们会记录Border Collie最近的分类及距离:这对犬种是(0, 8),即下标为0的Border Collie和下标为8的Portuguese WD,距离是0.232。
距离相等的问题以及为何要使用元组
你也许注意到了,Portuguese WD和Standard Poodle的距离是0.566,Boston Terrier和Brittany Spaniel的距离也是0.566,
如果我们通过最短距离来取,很可能会取出Standard Poodle和Boston Terrier进行组合,这显然是错误的,所以我们才会使用元组来存放这对犬种的下标,以作判断。比如说,Portuguese WD的记录是:
['Portuguese Water Dog', 0.566, (8, 9)]
它的近邻Standard Poodle的记录是:
['Standard Poodle', 0.566, (8, 9)]
我们可以通过这个元组来判断这两条记录是否是一对。
距离相等的另一个问题
在介绍优先队列时,我用了歌手的年龄举例,如果他们的年龄相等,取出的顺序又是怎样的呢?

可以看到,如果年龄相等,优先队列会根据记录中的第二个元素进行判断,即歌手的姓名,并按字母顺序返回,如Avaka会比Moa优先返回。
在犬种示例中,我们让距离成为第一优先级,下标成为第二优先级。因此,我们插入到优先队列的一条完整记录是这样的:
重复下述步骤,直到仅剩一个分类
我们从优先队列中取出两个元素,对它们进行合并。如合并Border Collie和Portuguese WD后,会形成一个新的分类:
['Border Collie', 'Portuguese WD']
然后我们需要计算新的分类和其它分类之间的距离,方法是对取出的两个分类的距离字典进行合并。如第一个分类的距离字段是distanceDict1,第二个分类的是distanceDict2,新的距离字段是newDistanceDict:
初始化newDistanceDict
对于distanceDict1的每一个键值对:
如果这个键在distanceDict2中存在:
如果这个键在distanceDict1中的距离要比在distanceDict2中的距离小:
将distanceDict1中的距离存入newDistanceDict
否则:
将distanceDict2中的距离存入newDistanceDict

经过计算后,插入到优先队列中的新分类的完整记录是:

代码实践
你能将上面的算法用Python实现吗?你可以从hierarchicalClustererTemplate.py这个文件开始,完成以下步骤:
- 编写init方法,对于每条记录:
- 计算该分类和其它分类之间的欧几里得距离;
- 找出该分类的近邻;
- 将这些信息放到优先队列的中。
- 编写cluster方法,重复以下步骤,直至剩下一个分类:
- 从优先队列中获取两个元素;
- 合并;
- 将合并后的分类放回优先队列中。

解答
注意,我的实现并不一定是最好的,你可以写出更好的!
from queue import PriorityQueue
import math
"""
层次聚类示例代码
"""
def getMedian(alist):
"""计算中位数"""
tmp = list(alist)
tmp.sort()
alen = len(tmp)
if (alen % 2) == 1:
return tmp[alen // 2]
else:
return (tmp[alen // 2] + tmp[(alen // 2) - 1]) / 2
def normalizeColumn(column):
"""计算修正的标准分"""
median = getMedian(column)
asd = sum([abs(x - median) for x in column]) / len(column)
result = [(x - median) / asd for x in column]
return result
class hClusterer:
"""该聚类器默认数据的第一列是标签,其它列是数值型的特征。"""
def __init__(self, filename):
file = open(filename)
self.data = {}
self.counter = 0
self.queue = PriorityQueue()
lines = file.readlines()
file.close()
header = lines[0].split(',')
self.cols = len(header)
self.data = [[] for i in range(len(header))]
for line in lines[1:]:
cells = line.split(',')
toggle = 0
for cell in range(self.cols):
if toggle == 0:
self.data[cell].append(cells[cell])
toggle = 1
else:
self.data[cell].append(float(cells[cell]))
# 标准化特征列(即跳过第一列)
for i in range(1, self.cols):
self.data[i] = normalizeColumn(self.data[i])
###
### 数据已经读入内存并做了标准化,对于每一条记录,将执行以下步骤:
### 1. 计算该分类和其他分类的距离,如当前分类的下标是1,
### 它和下标为2及下标为3的分类之间的距离用以下形式表示:
### {2: ((1, 2), 1.23), 3: ((1, 3), 2.3)... }
### 2. 找出距离最近的分类;
### 3. 将该分类插入到优先队列中。
###
# 插入队列
rows = len(self.data[0])
for i in range(rows):
minDistance = 99999
nearestNeighbor = 0
neighbors = {}
for j in range(rows):
if i != j:
dist = self.distance(i, j)
if i < j:
pair = (i,j)
else:
pair = (j,i)
neighbors[j] = (pair, dist)
if dist < minDistance:
minDistance = dist
nearestNeighbor = j
nearestNum = j
# 记录这两个分类的配对信息
if i < nearestNeighbor:
nearestPair = (i, nearestNeighbor)
else:
nearestPair = (nearestNeighbor, i)
# 插入优先队列
self.queue.put((minDistance, self.counter,
[[self.data[0][i]], nearestPair, neighbors]))
self.counter += 1
def distance(self, i, j):
sumSquares = 0
for k in range(1, self.cols):
sumSquares += (self.data[k][i] - self.data[k][j])**2
return math.sqrt(sumSquares)
def cluster(self):
done = False
while not done:
topOne = self.queue.get()
nearestPair = topOne[2][1]
if not self.queue.empty():
nextOne = self.queue.get()
nearPair = nextOne[2][1]
tmp = []
## 我从队列中取出了两个元素:topOne和nextOne,
## 检查这两个分类是否是一对,如果不是就继续从优先队列中取出元素,
## 直至找到topOne的配对分类为止。
while nearPair != nearestPair:
tmp.append((nextOne[0], self.counter, nextOne[2]))
self.counter += 1
nextOne = self.queue.get()
nearPair = nextOne[2][1]
## 将不处理的元素退回给优先队列
for item in tmp:
self.queue.put(item)
if len(topOne[2][0]) == 1:
item1 = topOne[2][0][0]
else:
item1 = topOne[2][0]
if len(nextOne[2][0]) == 1:
item2 = nextOne[2][0][0]
else:
item2 = nextOne[2][0]
## curCluster即合并后的分类
curCluster = (item1, item2)
## 对于这个新的分类需要做两件事情:首先找到离它最近的分类,然后合并距离字典。
## 如果item1和元素23的距离是2,item2和元素23的距离是4,我们取较小的那个距离,即单链聚类。
minDistance = 99999
nearestPair = ()
nearestNeighbor = ''
merged = {}
nNeighbors = nextOne[2][2]
for (key, value) in topOne[2][2].items():
if key in nNeighbors:
if nNeighbors[key][1] < value[1]:
dist = nNeighbors[key]
else:
dist = value
if dist[1] < minDistance:
minDistance = dist[1]
nearestPair = dist[0]
nearestNeighbor = key
merged[key] = dist
if merged == {}:
return curCluster
else:
self.queue.put( (minDistance, self.counter,
[curCluster, nearestPair, merged]))
self.counter += 1
def printDendrogram(T, sep=3):
"""打印二叉树状图。树的每个节点是一个二元组。这个方法摘自:
http://code.activestate.com/recipes/139422-dendrogram-drawing/"""
def isPair(T):
return type(T) == tuple and len(T) == 2
def maxHeight(T):
if isPair(T):
h = max(maxHeight(T[0]), maxHeight(T[1]))
else:
h = len(str(T))
return h + sep
activeLevels = {}
def traverse(T, h, isFirst):
if isPair(T):
traverse(T[0], h-sep, 1)
s = [' ']*(h-sep)
s.append('|')
else:
s = list(str(T))
s.append(' ')
while len(s) < h:
s.append('-')
if (isFirst >= 0):
s.append('+')
if isFirst:
activeLevels[h] = 1
else:
del activeLevels[h]
A = list(activeLevels)
A.sort()
for L in A:
if len(s) < L:
while len(s) < L:
s.append(' ')
s.append('|')
print (''.join(s))
if isPair(T):
traverse(T[1], h-sep, 0)
traverse(T, maxHeight(T), -1)
filename = '/Users/raz/Dropbox/guide/data/dogs.csv'
hg = hClusterer(filename)
cluster = hg.cluster()
printDendrogram(cluster)
运行结果和我们手算的一致:

动手实践
这里提供了77种早餐麦片的营养信息,包括以下几项:
- 麦片名称
- 热量
- 蛋白质
- 脂肪
- 纳
- 纤维
- 碳水化合物
- 糖
- 钾
- 维生素

请对这个数据集进行层次聚类:
- 哪种麦片和Trix最相近?
- 与Muesli Raisins & Almonds最相近的是?
结果
我们只需将代码中的文件名替换掉就可以了,结果如下:

因此Trix和Fruity Pebbles最相似(你可以去买这两种麦片尝尝)。Muesli Raisins & Almonds和Muesli Peaches & Pecans最相似。

好了,这就是层次聚类算法,很简单吧!