混淆矩阵

目前我们衡量分类器准确率的方式是使用以下公式:正确分类的记录数÷记录总数。
有时我们会需要一个更为详细的评价结果,这时就会用到一个称为混淆矩阵的可视化表格。
表格的行表示测试用例实际所属的类别,列则表示分类器的判断结果。
混淆矩阵可以帮助我们快速识别出分类器到底在哪些类别上发生了混淆,因此得名。
让我们看看运动员的示例,这个数据集中有300人,使用十折交叉验证,其混淆矩阵如下:

可以看到,100个体操运动员中有83人分类正确,17人被错误地分到了马拉松一列;92个篮球运动员分类正确,8人被分到了马拉松;85个马拉松运动员分类正确,9人被分到了体操,16人被分到了篮球。
混淆矩阵的对角线(绿色字体)表示分类正确的人数,因此求得的准确率是:
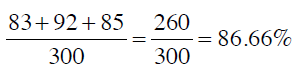
从混淆矩阵中可以看出分类器的主要问题。
在这个示例中,我们的分类器可以很好地区分体操运动员和篮球运动员,而马拉松运动员则比较容易和其他两个类别发生混淆。

怎样,是不是觉得混淆矩阵其实并不混淆呢?