使用Python编写朴素贝叶斯分类器
上例的数据格式如下:
both sedentary moderate yes i100
both sedentary moderate no i100
health sedentary moderate yes i500
appearance active moderate yes i500
appearance moderate aggressive yes i500
appearance moderate aggressive no i100
health moderate aggressive no i500
both active moderate yes i100
both moderate aggressive yes i500
appearance active aggressive yes i500
both active aggressive no i500
health active moderate no i500
health sedentary aggressive yes i500
appearance active moderate no i100
health sedentary moderate no i100
虽然这个这个例子中只有15条数据,但是我们还是保留十折交叉验证的过程,以便用于更大的数据集。十折交叉验证要求数据集等分成10份,这个例子中我们简单地将15条数据全部放到一个桶里,其它桶留空。
朴素贝叶斯分类器包含两个部分:训练和分类。
训练
训练的输出结果应该是:
- 先验概率,如P(i100) = 0.4;
- 条件概率,如P(健康|i100) = 0.167
我们使用如下代码表示先验概率:
self.prior = {'i500': 0.6, 'i100': 0.4}
条件概率的表示有些复杂,用嵌套的字典来实现:
{'i500': {1: {'appearance': 0.3333333333333333, 'health': 0.4444444444444444,
'both': 0.2222222222222222},
2: {'active': 0.4444444444444444, 'sedentary': 0.2222222222222222,
'moderate': 0.3333333333333333},
3: {'aggressive': 0.6666666666666666, 'moderate': 0.3333333333333333},
4: {'yes': 0.6666666666666666, 'no': 0.3333333333333333}},
'i100': {1: {'both': 0.5, 'health': 0.16666666666666666,
'appearance': 0.3333333333333333},
2: {'active': 0.3333333333333333, 'sedentary': 0.5,
'moderate': 0.16666666666666666},
3: {'aggressive': 0.16666666666666666, 'moderate': 0.8333333333333334},
4: {'yes': 0.3333333333333333, 'no': 0.6666666666666666}}}
1、2、3、4表示第几列,所以第一行可以解释为购买i500的顾客中运动目的是外表的概率是0.333。
首先我们要来进行计数,比如以下几行数据:
both sedentary moderate yes i100
both sedentary moderate no i100
health sedentary moderate yes i500
appearance active moderate yes i500
我们用字典来统计每个模型的次数,变量名为classes,逐行扫描后的结果是:
# 第一行
{'i100': 1}
# 第二行
{'i100': 2}
# 第三行
{'i500': 1, 'i100': 2}
# 全部
{'i500': 9, 'i100': 6}
要获取模型的先验概率,只要将计数结果除以总数就可以了。
计算后验概率也需要计数,变量名为counts。这个字典较为复杂,如扫完第一行第一列的结果是:
{'i100': {1: {'both': 1}}}
处理完所有数据后的计数结果是:
{'i500': {1: {'appearance': 3, 'health': 4, 'both': 2},
2: {'active': 4, 'sedentary': 2, 'moderate': 3},
3: {'aggressive': 6, 'moderate': 3},
4: {'yes': 6, 'no': 3}},
'i100': {1: {'both': 3, 'health': 1, 'appearance': 2},
2: {'active': 2, 'sedentary': 3, 'moderate': 1},
3: {'aggressive': 1, 'moderate': 5},
4: {'yes': 2, 'no': 4}}}
计算概率时,只需将计数除以该模型的总数就可以了:
P(外表|i100) = 2 / 6 = 0.333
以下是训练用的Python代码:
class Classifier:
def __init__(self, bucketPrefix, testBucketNumber, dataFormat):
"""bucketPrefix 分桶数据集文件前缀
testBucketNumber 测试桶编号
dataFormat 数据格式,形如:attr attr attr attr class
"""
total = 0
classes = {}
counts = {}
# 从文件中读取数据
self.format = dataFormat.strip().split('\t')
self.prior = {}
self.conditional = {}
# 遍历十个桶
for i in range(1, 11):
# 跳过测试桶
if i != testBucketNumber:
filename = "%s-%02i" % (bucketPrefix, i)
f = open(filename)
lines = f.readlines()
f.close()
for line in lines:
fields = line.strip().split('\t')
ignore = []
vector = []
for i in range(len(fields)):
if self.format[i] == 'num':
vector.append(float(fields[i]))
elif self.format[i] == 'attr':
vector.append(fields[i])
elif self.format[i] == 'comment':
ignore.append(fields[i])
elif self.format[i] == 'class':
category = fields[i]
# 处理该条记录
total += 1
classes.setdefault(category, 0)
counts.setdefault(category, {})
classes[category] += 1
# 处理各个属性
col = 0
for columnValue in vector:
col += 1
counts[category].setdefault(col, {})
counts[category][col].setdefault(columnValue, 0)
counts[category][col][columnValue] += 1
# 计数结束,开始计算概率
# 计算先验概率P(h)
for (category, count) in classes.items():
self.prior[category] = count / total
# 计算条件概率P(h|D)
for (category, columns) in counts.items():
self.conditional.setdefault(category, {})
for (col, valueCounts) in columns.items():
self.conditional[category].setdefault(col, {})
for (attrValue, count) in valueCounts.items():
self.conditional[category][col][attrValue] = (
count / classes[category])
self.tmp = counts
分类
分类函数会这样使用:
c.classify(['health', 'moderate', 'moderate', 'yes'])
我们需要计算:
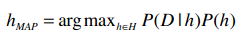
def classify(self, itemVector):
"""返回itemVector所属类别"""
results = []
for (category, prior) in self.prior.items():
prob = prior
col = 1
for attrValue in itemVector:
if not attrValue in self.conditional[category][col]:
# 属性不存在,返回0概率
prob = 0
else:
prob = prob * self.conditional[category][col][attrValue]
col += 1
results.append((prob, category))
# 返回概率最高的结果
return(max(results)[1])
让我们测试一下:
>>> c = Classifier('iHealth/i', 10, 'attr\tattr\tattr\tattr\tclass')
>>> c.classify(['health' 'moderate', 'moderate', 'yes'])
i500
