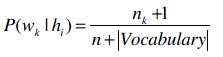面向程序员的数据挖掘指南
Introduction
简介
序
数据挖掘简介及如何使用本书
欢迎来到21世纪
本书的结构
推荐系统入门
你喜欢的东西我也喜欢
使用Python代码来表示数据
最后一个公式:余弦相似度
Python推荐模块
隐式评价和基于物品的过滤算法
显式评价&隐式评价
显式评价的问题
什么会阻碍你成功?
基于用户/物品的协同过滤
修正的余弦相似度
Slope One算法
使用Python实现Slope One算法
分类
根据物品特征进行分类
回到潘多拉
她是从事什么运动的?
Python编码
每加仑燃油可以跑多少公里?
番外篇:关于标准化
进一步探索分类
效果评估算法和kNN
留一法
混淆矩阵
代码示例
Kappa指标
优化近邻算法
新的数据集,新的挑战
朴素贝叶斯
朴素贝叶斯
微软购物车
贝叶斯法则
为什么我们需要贝叶斯法则?
i100、i500健康手环
使用Python编写朴素贝叶斯分类器
共和党还是民主党
数值型数据
使用Python实现
朴素贝叶斯算法和非结构化文本
非结构化文本的分类算法
训练阶段
使用朴素贝叶斯进行分类
新闻组语料库
朴素贝叶斯与情感分析
聚类
层次聚类法
编写层次聚类算法
k-means聚类算法
安然事件
Powered by
GitBook
训练阶段
训练阶段
首先,我们统计所有文本中一共出现了多少个不同的单词,记作“|Vocabulary|”(总词汇表)。
对于每个单词w
k
,我们将计算P(w
k
|h
i
),每个h
i
(喜欢和讨厌两种)的计算步骤如下:
将该分类下的所有文章合并到一起;
统计每个单词出现的数量,记为n;
对于总词汇表中的单词w
k
,统计他们在本类文章中出现的次数n
k
:
最后应用下方的公式:
results matching "
"
No results matching "
"