番外篇:关于标准化
这一章我们讲解了标准化的重要性,即当不同特征的评分尺度不一致时,为了得到更准确的距离结果,就需要将这些特征进行标准化,使他们在同一个尺度内波动。

虽然大多数数据挖掘工程师对标准化的理解是一致的,但也有一些人要将这种做法区分为“正规化”和“标准化”两种。
其中,“正规化”表示将值的范围缩小到0和1之间;“标准化”则是将特征值转换为均值为0的一组数,其中每个数表示偏离均值的程度(即标准偏差或绝对偏差)。我们使用的修正的标准分就是属于后者。
回忆一下,我们上文中有讲解过如何将特征值缩小到0到1之间:找出最大最小值,并做如下计算:
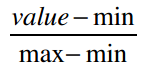
我们来比较一下使用不同的标准化方法得到的准确度:
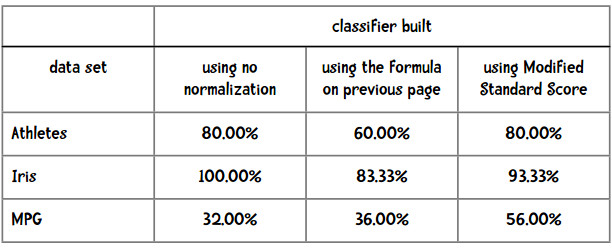
看来还是使用修正的标准分结果会好些。

用不同的数据集来测试我们的算法是不是很有趣?
这些数据集是从UCI机器学习仓库中获得的。去下载一些新的数据集,调整一下格式,测试我们学过的算法吧!